![[논문] 오토인코더 - Training Deep AutoEncoders for Collaborative Filtering](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb1gJc1%2FbtqYDkeMyne%2FAAAAAAAAAAAAAAAAAAAAAMgfUsNBYih_E-NCvfvdrhr5yiWoaMVGeENDh5QcQfzr%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D3sNDMXQPYBNSFxt%252B3v8s5%252BPeLOY%253D)
논문 arxiv.org/pdf/1708.01715.pdf
코드 https://github.com/NVIDIA/DeepRecommender
Training Deep AutoEncoders for Collaborative Filtering
개인적 요약
인코더와 디코더를 사용하는 구조이다.
인코더와 디코더는 서로의 구조가 미러링 되어있다. 입력을 받으면 인코더를 거치며 차원을 줄여 z를 만든 후 z를 디코더에 넣어 다시 원복하는 과정을 거친다. 이 과정을 거치면 sparse하던 데이터가 dense하게 바뀌는 원리이다. 따라서 차원축소로도 볼 수 있다.
f를 모델, 활성함수라고 했을 때 f(x) = y이다. 출력은 입력을 최대한 원상복귀해야 하기에 수식상 f(x) = x를 만족시켜야 하며 즉 f(y) = y를 만족시켜야 한다.
반복적인 re-feeding이 필요하며 드롭아웃을 필수로 하는 것 같다. 이 논문에서는 활성함수로 SELU를 썼다.
Abstract
추천 시스템의 평점 예측을 처리한다.
딥오토인코더의 6개 레이어와 어떤 layer-wise pre-training 없이 end-to-end로 처리되는 것을 기반으로 한다.
다음을 실험적으로 입증한다.
a) 깊은 오토인코더가 얕은 것보다 좋다.
b) 음수 부분에서 비선형 활성함수가 딥 모델에 중요하다.
c) 드롭아웃같은 정규화 기술이 오버피팅 예방을 위해 필요하다.
우리는 또한 협업필터링의 자연적인 sparse를 극복하기 위한 반복적인 출력을 re-feeding하는 학습 알고리즘을 제안한다. 이 알고리즘은 학습 속도를 향상시키고 모델 성능을 개선한다.
Introduction
협업필터링에 대한 내용
1.1 Relation work
2. model
user-based autoencoder에서 시작했다.
어떤 사전학습도 없이 사용하기 위해서 다음이 필요하다. (c는 어디?)
a) SELU를 사용
b) 높은 비율의 드롭아웃을 해야한다.
d) 학습동안 반복적인 출력 re-feeding이 필요
오토인코더는 인코더와 디코더, 두개의 요소로 구성된 네트워크이다.
encoder(x) : Rn-> Rd / decoder(z) : Rd -> Rn
목표는 최종 결과와 입력 결과간 오차를 최대한 줄이는 오류 측정을 위한 d dimensional representation을 얻는것이다.
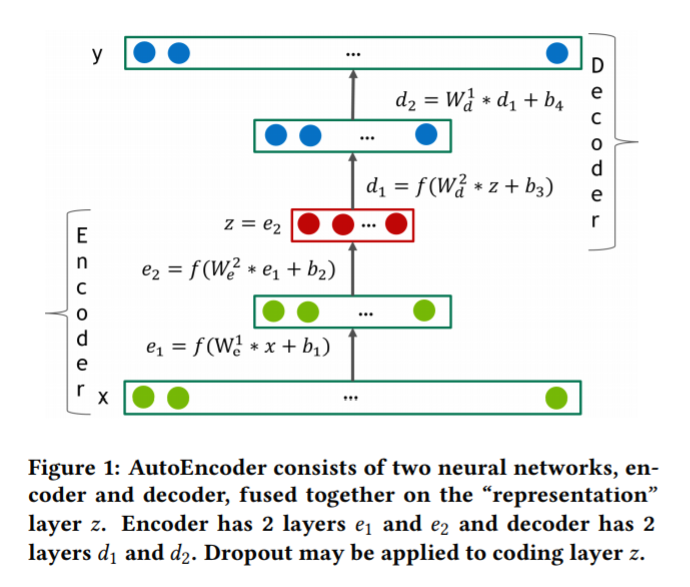
위 그림은 전형적인 4개 레이어를 가지는 오토인코더이다.
만약 인코딩 단계에 노이즈가 추가되면 de-noising이라고 부른다.
오토인코더는 차원축소기술이며 PCA와 유사하게 생각될 수 있다. 비선형 활성함수가 없는 오토인코더는 MSE loss를 쓸때 PCA 변환을 학습할 수 있어야 한다.
인코더와 디코더는 FC 순전파 신경망 레이어로 구성되어 있다. 식은 f(W*x + b)이고 f는 비선형 활성함수이다.
활성함수의 범위가 데이터보다 작다면 디코더의 마지막 레이어를 선형으로 유지해야 한다.
히든 레이어에서 활성함수가 0이 아닌 음의 부분을 포함하는 것이 매우 중요하며, 논문에서는 SELU를 주로 사용하였다.
디코더가 인코더 구조를 미러링하면 디코더의 w를 해당 계층에서 전치된 인코더의 w와 동일하도록 제한할 수 있다.
이러한 오토인코더를 constrained 혹은 tied라고 부르며 제한되지 않은것보다 파라미터가 거의 두배정도 적다.
순전파와 인퍼런스 : 순전파를 진행하는 동안 모델은 학습데이터 속 평점의 벡터정보로 사용자를 나타낸다. 학습 데이터는 sparse하지만 디코더의 출력은 dense하고 모든 아이템에 대해 평점을 예측한 정보를 포함한다.
2.1 Loss function
유저의 벡터 표현을 0으로 예측하는 것은 말이 안되므로 MMSE loss를 따른다.
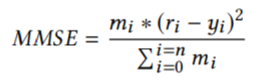
r : 실제 평점 y : 예측평점 m : mask함수 (r≠0이면 m=1, 나머지는 m=0)
RMSE = √MMSE
2.2 Dense re-feeding
입력은 sparse, 출력은 dense하다.
완벽한 f의 시나리오를 생각하보자.
유저가 새로운 아이템 k에 대해 평점을 매기고 그에 대한 백터 x'가 생성된다면 f(x) = x' / f(x) = f(x')가 된다.
그러므로 y=f(x)는 잘 훈련된 오토인코더 : f(y) = y 의 고정 지점이어야 한다.
고정지점을 잡고 dense한 업데이트를 위해 우리는 다음과 같은 dense re-feeding step의 반복으로 모든 옵티마이저 반복을 증가시켜야한다.
(1) 주어진 sparse x에 대해 equation 1을 사용하여 dense f(x)와 loss를 계산한다. (forward pass)
(2) 그리디언트를 계산하고 w를 업데이트한다. (backward pass)
(3) f(x)를 새로 처리하고 f(f(x))를 계산한다. 이제 f(x)와 f(f(x))는 dense하고 equation에서 온 loss는 모든 0이 아닌 m을 가진다. (두번째 forward pass)
(4) 그리디언트를 계산하고 w를 업데이트한다. (두번째 backward pass)
모든 반복에서 (3)과 (4)는 한번 이상 수행될 수 있다.
3. EXPERMENTS AND RESULTS
3.1 Experiment setup
넷플릭스 데이터를 시간을 기준으로 학습데이터와 테스트데이터로 나누었다. 학습 데이터는 테스트 데이터보다 먼저 평가한것을 포함한다. 테스트 데이터는 랜덤하게 test와 val 데이터로 나누었으며 각 평점들은 각 데이터에 나타날 확률이 50%이다. 학습데이터에 나타나지 않은 유저나 아이템은 test와 val에서 제거했다.
본 논문에서 학습시에는 배치사이즈는 128로, 0.9의 momentum을 사용한 SGD로, learning rate는 0.001로 하여 진행하였다. 파라미터 초기화는 xavier를 사용하였다. [18]과 달리 계층별 사전학습을 진행하지 않았다. 논문에서는 알맞은 활성함수 사용으로 인해 이가 가능했다고 생각한다.
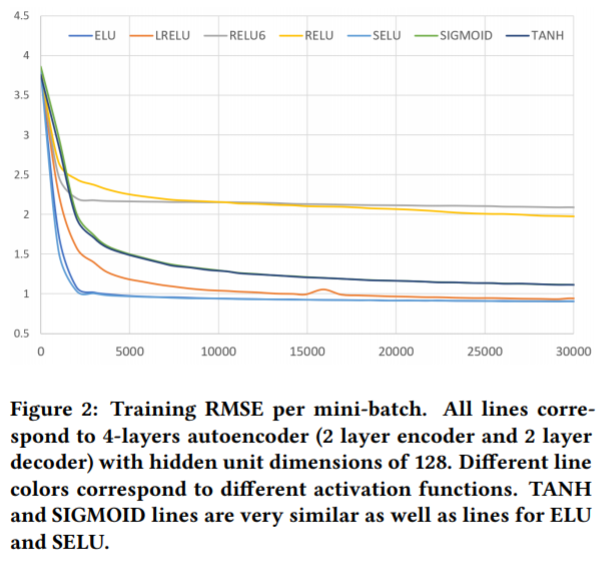
3.2 Effects of the activation types
SIGMOID, RELU, max(relu(x), 6) - RELU6, TANH, ELU, Leaky RELU, SELU 를 사용해보았다. 4개의 레이어(인코더 2개, 디코더 2개) 오토인코더와 히든 레이어당 128개의 유닛(차원)을 이용하였다. 평점은 1부터 5의 값을 가지고 디코더의 마지막 레이어를 sigmoid나 tanh를 통해 선형적으로 바꾸어야 하기 때문이다. 모든 다른 모델에서 활성 함수는 모든 레이어에 적용되었다.
결과는 ELU, SELU, LRELU > SIGMOID, RELU, RELU6, TANH 의 성능을 보였다. 이렇게 분리하는데에는 두가지의 속성을 보였다. a) 0이 아닌 음수 부분 b) 무한대의 양수 부분 이다. 그러므로 이 두가지는 성공적인 학습에 중요하다 볼 수 있다. 따라서 논문에서 성능을 위해 SELU 활성화 함수를 사용하고 SELU 기반의 네트워크를 튜닝하였다.
3.3 Over-fitting the data
477000명 유저들에게 주어진 9800만개의 평점을 가진 큰 데이터를 학습했다. 아이템의 수(영화의 수)는 n=17768개이다. 그러므로 첫번째 인코더 레이어는 d*n+d의 w를 가진다. (d는 레이어의 유닛 수)
현대의 딥러닝과 하드웨어에 비하면 이정도는 작은 태스크이다. 하나의 인코더와 디코더로 시작한다면 512만큼 작은 d이더라도 학습데이터에 오버피팅된다. 제한이 없는 인코더에 제한을 걸면 오버피팅이 감소되지만 완벽하게 문제를 해결하진 않는다.
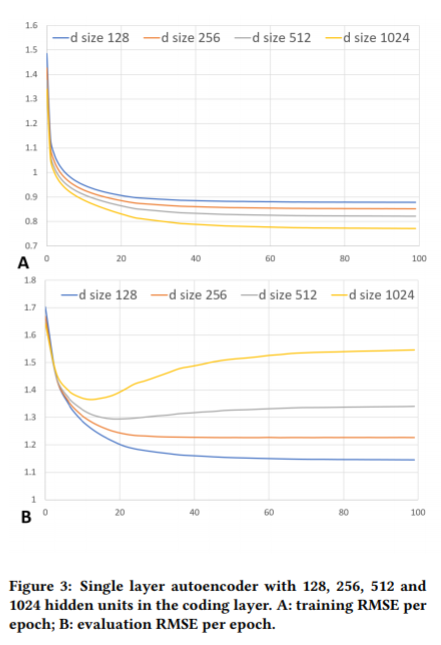
3.4 Going deeper
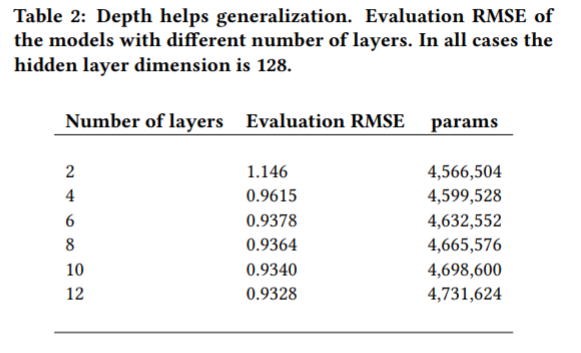
레이어를 넓게 하면 loss를 줄이는데에 도움이 되고, 레이어를 추가하면 주로 네트워크 성능을 일반화하는데에 관련된다. 실험에서 오버피팅을 피하기 위해 모든 히든레이어에 대해 충분히 작은 차원(d=128)을 선택하였고 레이어를 추가로 쌓기 시작했다. Table2에서 레이어의 수와 평가 정확도에 관해 긍정적인 관련을 볼 수 있다.
인코더와 디코더에서 레이어를 하나에서 세개로 늘리는 것은 RMSE 평가에 좋은 개선을 보인다. (1.146에서 0.9378로) 그뒤 무작정 레이어를 추가하는 것은 도움이 되지만 반환이 줄어드는 것을 볼 수 있다. 인코더와 디코더에서 하나의 d=256인 레이어를 가지는 모델은 9,115,240개의 파라미터를 가진다. 이는 비슷한 딥 모델보다 거의 2배의 파라미터를 가지면서도 RMSE 평가가 더 나쁘다.
3.5 Dropout
3.4에서 작은 레이어를 아주 많이 추가하는 것은 결국 반환을 줄이는 것을 볼 수 있다. 그러므로 우리는 모델 구조와 하이퍼 파라미터를 광범위하게 시작했다. 우리의 대부분의 약속한 모델은 다음과 같은 구조를 가진다. - n, 512, 512, 1024, 512, 512, n - 인코더는 3개의 레이어 (512, 512, 1024), 1024레이어에 대한 코딩, 디코더는 3개의 레이어(512, 512, n). 그러나 이 모델은 정규화가 없으면 빠르게 오버피팅 된다. 정규화를 위해 우리는 드롭아웃을 시도했고 높은 비율(0.8)의 드롭아웃이 가장 좋은 모습을 보였다. 드롭아웃은 인코더의 출력에만 적용했다. [f (x) = decode(dropout(encode(x)))] 모든 레이어에 드롭아웃을 시도해보았는데 학습의 집합을 방해하고 일반화를 개선시키지 못했다.

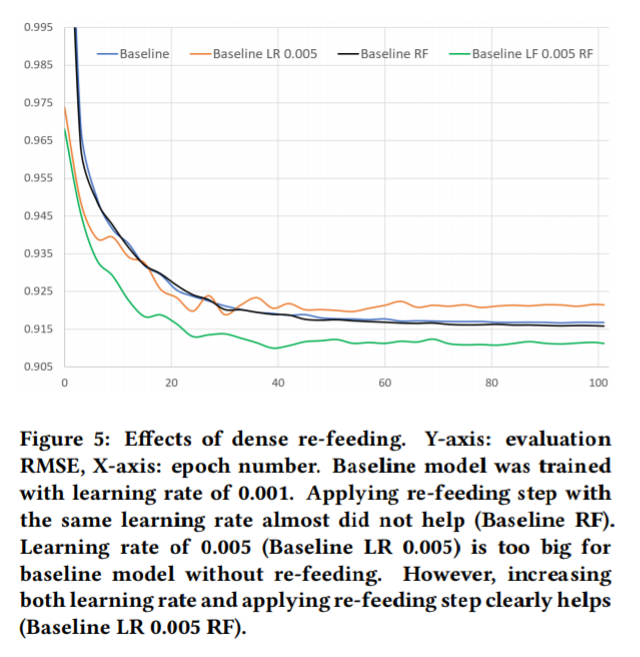
3.6 Dense re-feeding
dense re-feeding의 반복은 6레이어[n, 512, 512, 1024, dp(0.8), 512, 512,n] 모델의 향상된 정확도 평가를 제공한다. 각 파라미터는 입력, 히든유닛, 출력과 dp(0.8)의 수를 표기한다. 단순히 출력을 re-feeding하는 것은 모델 성능에 상당한 역할을 하지 못한다. 그러나 높은 learning late와 함께하면 성능 개선에 상당히 기여한다. 참고로 높은 learning late(0.005)에 dense re-feeding을 하지 않으면 모델이 틀어져서 시작한다.
dense re-feeding과 learing late의 증가는 RMSE를 0.9167에서 0.9100으로 개선시켰다. 최고 성능의 RMSE를 잡고 테스트 RMSE를 계산했을때 0.9099의 성능을 보였다. 이는 다른 방법들보다 더 낫다고 생각한다.
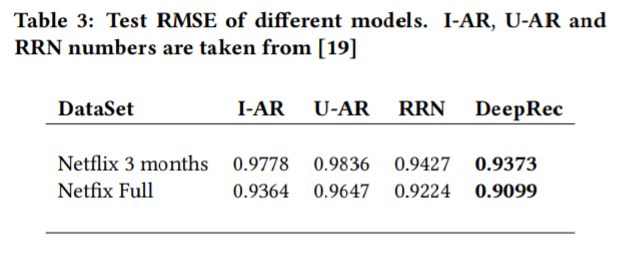
3.7 Comparison with other methods
우리는 같은 데이터에서 PMF [14], T-SVD [11], I/U-AR [17]를 능가한 현재의 추천 시스템 [19]와 우리의 제일 좋은 모델을 비교한다. 참고로 T-SVD, RRN과 다르게 우리는 평점에 대해 시간적인 dynamic 계산을 명시적으로 받아들이지 않는다. 하지만 Table 3는 미래 평점 예측에서 이러한 방법들을 능가할 수 있음을 보여준다. 우리는 각 보델을 트레인 세트만을 사용하여 100 epoch로 RMSE를 평가했다. 그 뒤 제일 좋은 성능의 RMSE를 체크포인트한 후 테스트 세트에 적용했다.
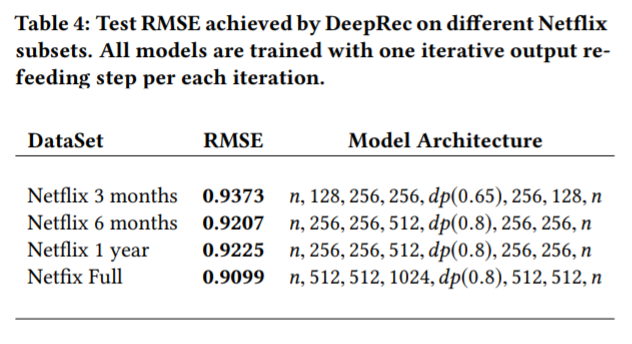
Netflix 3 months 데이터는 Netflix full 데이터보다 7배 적으므로 이 데이터만 학습했을 때 성능이 상당이 나쁜 것은 당연하다 (0.9373 vs 0.9099). 실은 Netflix full에서 최고 성능을 보인 모델은 이 세트에 오버피팅 되었고, 그에 따라 모델의 복잡도를 줄였다. (Table 4 참고)
[19] Chao-Yuan Wu, Amr Ahmed, Alex Beutel, Alexander J. Smola, and How Jing. 2017. Recurrent Recommender Networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (WSDM ’17). ACM, New York, NY, USA, 495–503. hps://doi.org/10.1145/3018661.3018689
4 CONCLUSION
이 논문은 깊은 오토인코더가 적은 양의 데이터에 대해 잘 구축된 기술과(드롭아웃) 비교적 최근의 딥러닝 기술(스케일된 지수 선형 유닛)을 사용하여 성공적인 학습을 할 수 있는 방법을 입증한다. 또한 협업 필터링으로 dense 업데이트를 할 수 있도록 하는 기술인 iterative output re-feeding, learing rate 증가, 모델의 일반화 성능 개선을 소개했다. 미래 평점 예측에서 이 모델은 추가적인 시간 시그널 없이 다른 접근법들을 능가한다.
우리는 아이템 기반 모델을 지원하지만 이는 유저 기반 모델보다 덜 실용적이다. 실제 세계의 추천 시스템은 유저가 아이템보다 많기 때문이다. 최종적으로, 개인적으로 추천시스템을 만들고 스케일링(크기 조정) 문제에 직면했을 때 샘플 아이템에겐 사용 가능하지만 유저에겐 아니다.
'AI > Model (Paper)' 카테고리의 다른 글
| Attention : NEURAL MACHINE TRANSLATIONBY JOINTLY LEARNING TO ALIGN AND TRANSLATE (0) | 2021.06.28 |
|---|---|
| [Seq2Seq] Sequence to Sequence Learning with Neural Networks (0) | 2021.06.19 |
| [코드] 오토인코더 - Training Deep AutoEncoders for Collaborative Filtering (0) | 2021.03.02 |
| (진행중)Transformer : Attention Is All You Need 리뷰 (0) | 2021.01.18 |
| (진행중)DETR : End-to-End Object Detection with Transformers 리뷰 (0) | 2021.01.05 |