
논문 : arxiv.org/pdf/1706.03762v5.pdf
코드 : https://tutorials.pytorch.kr/beginner/transformer_tutorial.html
Attention Is All You Need
NLP : (RNN -> (LSTM) -> seq2seq -> attention -> transformer)
Abstract
지배적인 순서 전래 모델은 복잡한 반복이나 인코더와 디코더를 포함하는 CNN에 기반을 둔다. 최고의 수행 모델은 또한 어텐션 방법을 통해 인코더와 디코더에 연결한다.
2 Background
- 순차계산을 줄이는 목표는 또한 Extended Neural GPU, ByteNet, ConvS2S의 기초를 형성하는데 이들은 빌딩블록에 기초를 둔 convolutional neural networks와 모든 입력과 출력 위치에 병행적으로 숨겨진 표현을 계산하는 것을 사용한다. 입력과 출력간 거리에 따른 위치에 관련된 시그널을 필요로하는 linearly for ConvS2S and logarithmically for ByteNet는 먼 거리에서 학습이 어렵다.
- Transformer는 지속적인 수의 operations으로, 비록 평균적인 어텐션-웨이트 위치때문에 감소된 효과적인 재해결의 비용에도 불구하고 Multi-Head Attention으로 효과를 낸다.
- 가끔 인트라 어텐션으로 불리는 셀프 어텐션은 다른 위치
- Transformer는 최초로 self-attention에 완벽히 의존하는 모델이다. 정렬된 시퀀스 RNN이나 컨벌루션을 사용하지 않는다.
3 Model Architecture
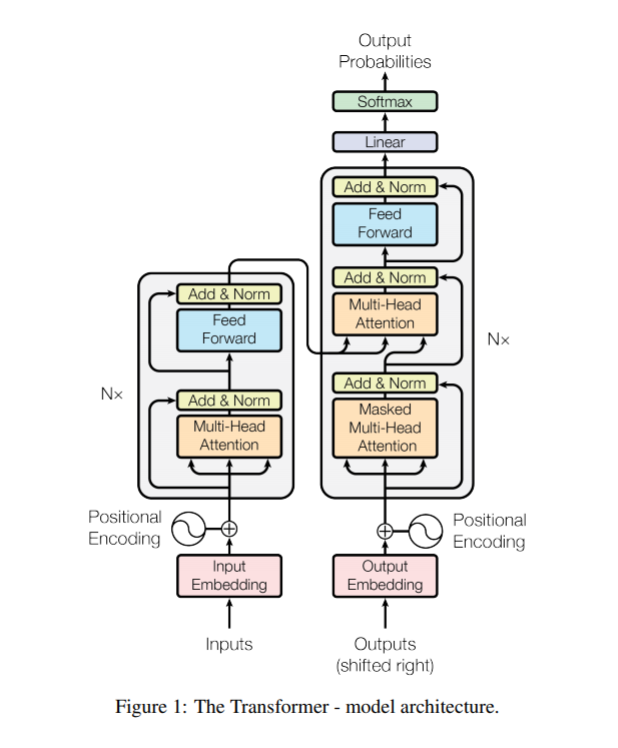
- 인코더, 디코더 구조를 사용한다.
- 기호 표현의 입력 시퀀스를 연속 표현 시퀀스(z)에 매핑한다.
- z가 주어지면 디코더는 한번에 한 요소의 출력 시퀀스를 생성한다.
- 각 스텝마다 모델은 자동 회귀한다 : 추가적인 다음에 생성하는 입력때 이전 생성된 기호를 소비하여
- Transformer는 Figure 1에서 보이는 왼쪽과 오른쪽 절반의 인코더와 디코더간 꽉찬 연결 레이어가 셀프어텐션과 포인트와이즈를 사용하여 전체 구조를 따른다.
3.1 Encoder and Decoder Stacks
Encoder
- 인코더는 N = 6 인 동일한 레이어가 쌓여 구성된다. 각 레이어는 두개의 서브레이어를 가진다. 첫번째는 multi-head attention이고 두번째는 위치별로 완전히 연결된 feed-forward이다.
- 우리는 각 두개의 서브 레이어에 잔여 연결을 사용하고 레이어 정규화를 수행한다. 즉, 각 서브레이어의 출력은 LayerNorm(x+서브레이어(x))이고, 서브레이어(x)는 스스로 구현된 기능에서 나왔다.
- 이 모든 서브레이어의 잔여 연결들의 용이를 위해 임베딩 레이어뿐만 아니라 모델의 출력 차원을 512로 제공한다.
Decoder
- 디코더 또한 N=6의 동일한 레이어 스택으로 구성된다. 추가로 인코더 레이어의 두 서브레이어에 디코더가 세번째 서브레이어를 삽입한다. 이것은 인코더 스택의 출력에 대해 multi-head attention을 수행한다.
- 인코더와 비슷하게, 우리는 각 서브레이어 주위에 잔여연결을 쓰고 레이어 정규화를 수행한다. 또한 우리는 디코더스택의 attention 서브레이어를 수정한다. 위치가 서브 순서 위치로 참석하는것을 예방하기 위해서이다.
- 출력 임베딩이 하나의 위치로 상쇄되는 사실과 결합한 이 마스킹은, 예측한 위치 i가 오직 i보다 적은 위치의 알려진 출력에만 의존하도록 보장한다.
3.2 Attention
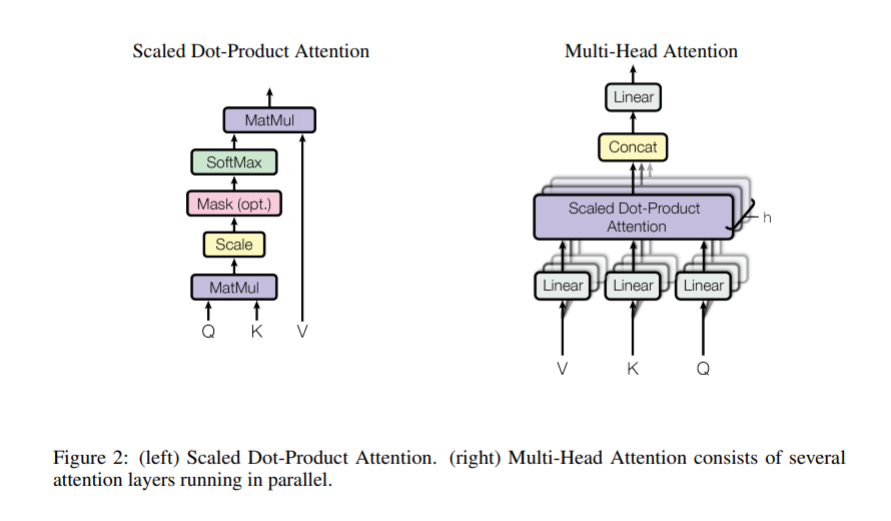
- attention은 쿼리, key, value, 출력이 모두 벡터인 출력에 쿼리와 key-value쌍을 매핑하는 것으로 설명될 수 있다.
- 출력은 값의 가중치합에 의해 계산된다. 각 값에 할당된 가중치는 해당하는 키와 쿼리의 호환 함수로 계산된다.
3.2.1 Scaled Dot-Product Attention
- 우리는 우리의 특정 attention을 "Scaled Dot-Product Attention" 라고 부른다. 입력은 쿼리, 키들의 차원(dk), 값들의 차원(dv)으로 구성된다. 우리는 모든 키로 쿼리의 곱을 계산하고, 각각 √ dk로 나눈 뒤 값에 softmax를 적용하여 값의 가중치를 구한다.
- 실제로 우리는 쿼리 셋에 대한 attention 함수를 행렬 Q와 같이 동시에 계산한다. 또한 키와 값들은 행렬 K와 V와 함께 묶인다. 우리는 출력 행렬을 다음과 같이 계산한다.
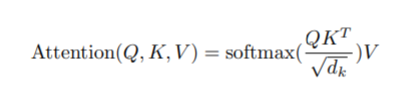
- 흔하게 attention으로 사용되는 두개는 additive attention과 dot-product (multiplicative) attention이다. Dot-product attention은 1/√dk의 스케일링 계수(scaling factor)를 제외하고 우리의 알고리즘과 동일하다. Additive attention은 하나의 은닉층의 feed-forward network를 사용하여 호환 함수를 계산한다. 두개는 이론적 복잡도가 유사하지만, dot-product attention은 높은 최적화 행렬 곱을 사용할 수 있기 때문에 더 빠르고 실제에서의 공간 효율이 높다.